
Introducción al uso de NLTK con Python
El procesamiento del lenguaje natural es un aspecto del aprendizaje automático que le permite procesar palabras escritas en un lenguaje amigable para las máquinas. Estos textos se pueden modificar y puedes ejecutar algoritmos computacionales en ellos como quieras.
La lógica detrás de esta tecnología cautivadora parece compleja, pero no lo es. E incluso ahora, con un conocimiento sólido de la programación básica de Python, puede crear un nuevo procesador de texto de bricolaje con el kit de herramientas de lenguaje natural (NLTK).
A continuación, le indicamos cómo comenzar con NLTK de Python.
¿Qué es NLTK y cómo funciona?
Escrito con Python, NLTK presenta una variedad de funcionalidades de manipulación de cadenas. Es una biblioteca de lenguaje natural versátil con un vasto repositorio de modelos para varias aplicaciones de lenguaje natural.
Con NLTK, puede procesar textos sin procesar y extraer características significativas de ellos. También ofrece modelos de análisis de texto, gramáticas basadas en características y ricos recursos léxicos para construir un modelo de lenguaje completo.
Cómo configurar NLTK
Primero, cree una carpeta raíz del proyecto en cualquier lugar de su PC. Para comenzar a usar la biblioteca NLTK, abra su terminal en la carpeta raíz que creó anteriormente y cree un entorno virtual .
Luego, instale el kit de herramientas de lenguaje natural en este entorno usando pip :
pip install nltkNLTK, sin embargo, presenta una variedad de conjuntos de datos que sirven como base para nuevos modelos de lenguaje natural. Para acceder a ellos, debe activar el descargador de datos integrado de NLTK.
Entonces, una vez que haya instalado NLTK con éxito, abra su archivo Python usando cualquier editor de código.
Luego importe el módulo nltk y cree una instancia del descargador de datos con el siguiente código:
pip install nltk
nltk.download()Al ejecutar el código anterior a través del terminal, aparece una interfaz gráfica de usuario para seleccionar y descargar paquetes de datos. Aquí, deberá elegir un paquete y hacer clic en el botón Descargar para obtenerlo.
Cualquier paquete de datos que descargue va al directorio especificado escrito en el campo Directorio de descarga . Puede cambiar esto si lo desea. Pero intente mantener la ubicación predeterminada en este nivel.
Nota: Los paquetes de datos se adjuntan a las variables del sistema de forma predeterminada. Por lo tanto, puede seguir usándolos para proyectos posteriores independientemente del entorno de Python que esté usando.
Cómo utilizar tokenizadores NLTK
En última instancia, NLTK ofrece modelos de tokenización entrenados para palabras y oraciones. Con estas herramientas, puede generar una lista de palabras a partir de una oración. O transforma un párrafo en una matriz de oraciones sensata.
A continuación, se muestra un ejemplo de cómo utilizar el tokenizador de palabras NLTK :
import nltk
from nltk.tokenize import word_tokenize
word = "This is an example text"
tokenWord = word_tokenizer(word)
print(tokenWord)
Output:
['This', 'is', 'an', 'example', 'text']NLTK también usa un tokenizador de oraciones previamente entrenado llamado PunktSentenceTokenizer . Funciona dividiendo un párrafo en una lista de oraciones.
Veamos cómo funciona esto con un párrafo de dos oraciones:
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
sentence = "This is an example text. This is a tutorial for NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(sentence)
print(tokenized_sentence)
Output:
['This is an example text.', 'This is a tutorial for NLTK']
Puede tokenizar aún más cada oración en la matriz generada a partir del código anterior usando word_tokenizer y Python for loop .
Ejemplos de cómo utilizar NLTK
Entonces, si bien no podemos demostrar todos los casos de uso posibles de NLTK, aquí hay algunos ejemplos de cómo puede comenzar a usarlo para resolver problemas de la vida real.
Obtenga definiciones de palabras y sus partes del discurso
NLTK presenta modelos para determinar las partes del discurso, obtener semántica detallada y el posible uso contextual de varias palabras.
Puede utilizar el modelo de wordnet para generar variables para un texto. Luego determine su significado y parte del discurso.
Por ejemplo, revisemos las posibles variables de "Monkey:"
import nltk
from nltk.corpus import wordnet as wn
print(wn.synsets('monkey'))
Output:
[Synset('monkey.n.01'), Synset('imp.n.02'), Synset('tamper.v.01'), Synset('putter.v.02')]
El código anterior genera posibles alternativas de palabras o sintaxis y partes de la oración para "Monkey".
Ahora verifique el significado de "Mono" usando el método de definición :
Monkey = wn.synset('monkey.n.01').definition()
Output:
any of various long-tailed primates (excluding the prosimians)Puede reemplazar la cadena entre paréntesis con otras alternativas generadas para ver qué salidas NLTK.
Sin embargo, el modelo pos_tag determina las partes del discurso de una palabra. Puede usar esto con word_tokenizer o PunktSentenceTokenizer () si está tratando con párrafos más largos.
Así es como funciona:
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
word = "This is an example text. This is a tutorial on NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(word)
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i)
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN'), ('.', '.')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]El código anterior empareja cada palabra tokenizada con su etiqueta de voz en una tupla. Puede comprobar el significado de estas etiquetas en Penn Treebank .
Para obtener un resultado más limpio, puede eliminar los puntos en la salida usando el método replace () :
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i.replace('.', ''))
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Cleaner output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]Visualización de tendencias de características usando NLTK Plot
Extraer características de textos sin formato suele ser tedioso y requiere mucho tiempo. Pero puede ver los determinantes de características más fuertes en un texto utilizando el gráfico de tendencia de distribución de frecuencia NLTK.
NLTK, sin embargo, se sincroniza con matplotlib. Puede aprovechar esto para ver una tendencia específica en sus datos.
El siguiente código, por ejemplo, compara un conjunto de palabras positivas y negativas en una gráfica de distribución usando sus dos últimos alfabetos:
import nltk
from nltk import ConditionalFreqDist
Lists of negative and positive words:
negatives = [
'abnormal', 'abolish', 'abominable',
'abominably', 'abominate','abomination'
]
positives = [
'abound', 'abounds', 'abundance',
'abundant', 'accessable', 'accessible'
]
# Divide the items in each array into labeled tupple pairs
# and combine both arrays:
pos_negData = ([("negative", neg) for neg in negatives]+[("positive", pos) for pos in positives])
# Extract the last two alphabets from from the resulting array:
f = ((pos, i[-2:],) for (pos, i) in pos_negData)
# Create a distribution plot of these alphabets
cfd = ConditionalFreqDist(f)
cfd.plot()La gráfica de distribución alfabética se ve así:
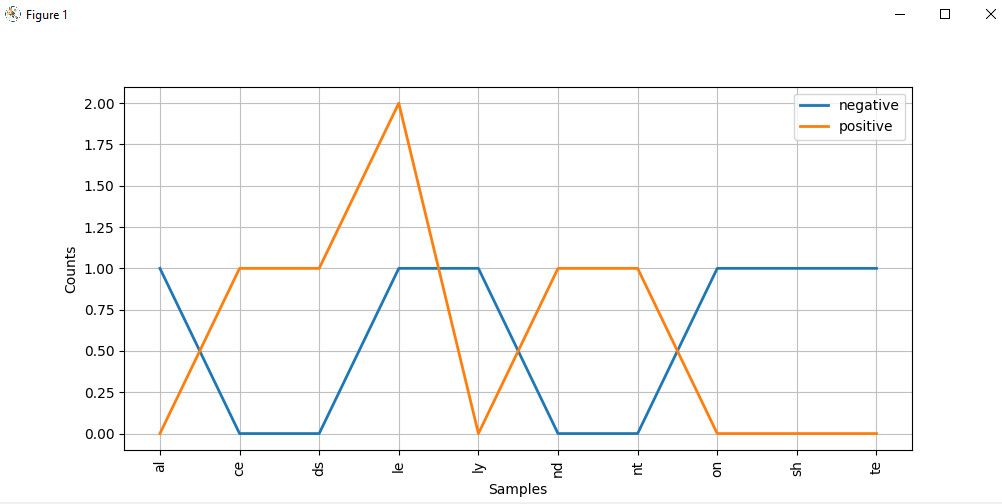
Mirando de cerca el gráfico, las palabras que terminan con ce , ds , le , nd y nt tienen una mayor probabilidad de ser textos positivos. Pero las que terminan con al , ly , on y te son probablemente palabras negativas.
Nota : Aunque hemos utilizado datos autogenerados aquí, puede acceder a algunos de los conjuntos de datos integrados de NLTK utilizando su lector de Corpus llamándolos desde la clase de corpus de nltk . Es posible que desee consultar la documentación del paquete corpus para ver cómo puede usarlo.
Siga explorando el kit de herramientas de procesamiento del lenguaje natural
Con la aparición de tecnologías como Alexa, detección de spam, chatbots, análisis de sentimientos y más, el procesamiento del lenguaje natural parece estar evolucionando hacia su fase infrahumana. Aunque solo hemos considerado algunos ejemplos de lo que ofrece NLTK en este artículo, la herramienta tiene aplicaciones más avanzadas que superan el alcance de este tutorial.
Después de leer este artículo, debería tener una buena idea de cómo usar NLTK en un nivel básico. ¡Todo lo que le queda por hacer ahora es poner este conocimiento en acción usted mismo!