
Cómo encontrar datos duplicados en un archivo de texto de Linux con uniq
¿Alguna vez te has encontrado con archivos de texto con líneas repetidas y palabras duplicadas? Tal vez trabaje regularmente con la salida de comandos y desee filtrarlos por cadenas distintas. Cuando se trata de archivos de texto y la eliminación de datos redundantes en Linux, el comando uniq es su mejor opción.
En este artículo, analizaremos el comando uniq en profundidad, junto con una guía detallada sobre cómo usar el comando para eliminar líneas duplicadas de un archivo de texto.
¿Qué es el comando uniq?
El comando uniq en Linux se usa para mostrar líneas idénticas en un archivo de texto. Este comando puede resultar útil si desea eliminar palabras o cadenas duplicadas de un archivo de texto. Dado que el comando uniq coincide con las líneas adyacentes para encontrar copias redundantes, solo funciona con archivos de texto ordenados.
Afortunadamente, puede canalizar el comando sort con uniq para organizar el archivo de texto de una manera que sea compatible con el comando. Además de mostrar líneas repetidas, el comando uniq también puede contar la aparición de líneas duplicadas en un archivo de texto.
Cómo usar el comando uniq
Hay varias opciones y banderas que puede usar con uniq. Algunos de ellos son básicos y realizan operaciones simples como imprimir líneas repetidas, mientras que otros son para usuarios avanzados que trabajan frecuentemente con archivos de texto en Linux.
Sintaxis básica
La sintaxis básica del comando uniq es:
uniq option input output… donde opción es la bandera utilizada para invocar métodos específicos del comando, la entrada es el archivo de texto para procesar y la salida es la ruta del archivo que almacenará la salida.
El argumento de salida es opcional y se puede omitir. Si un usuario no especifica el archivo de entrada, uniq toma datos de la salida estándar como entrada. Esto permite a un usuario canalizar uniq con otros comandos de Linux .
Archivo de texto de ejemplo
Usaremos el archivo de texto duplicate.txt como entrada para el comando.
127.0.0.1 TCP
127.0.0.1 UDP
Do catch this
DO CATCH THIS
Don't match this
Don't catch this
This is a text file.
This is a text file.
THIS IS A TEXT FILE.
Unique lines are really rare.
Tenga en cuenta que ya hemos ordenado este archivo de texto con el comando sort . Si está trabajando con algún otro archivo de texto, puede ordenarlo usando el siguiente comando:
sort filename.txt > sorted.txtEliminar líneas duplicadas
El uso más básico de uniq es eliminar cadenas repetidas de la entrada e imprimir una salida única.
uniq duplicate.txtProducción:
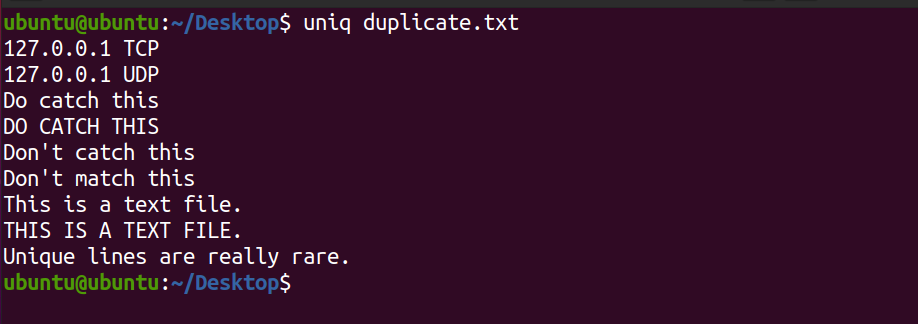
Observe que el sistema no muestra la segunda aparición de la línea. Este es un archivo de texto . Además, el comando antes mencionado solo imprime las líneas únicas en el archivo y no afecta el contenido del archivo de texto original.
Contar líneas repetidas
Para generar el número de líneas repetidas en un archivo de texto, use la marca -c con el comando predeterminado.
uniq -c duplicate.txtProducción:
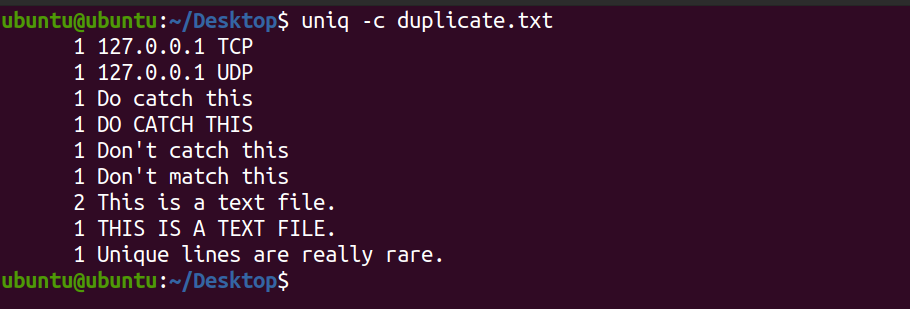
El sistema muestra el recuento de cada línea que existe en el archivo de texto. Puede ver que la línea Este es un archivo de texto aparece dos veces en el archivo. De forma predeterminada, el comando uniq distingue entre mayúsculas y minúsculas.
Imprimir solo líneas repetidas
Para imprimir solo líneas duplicadas del archivo de texto, use la marca -D . La -D significa duplicado .
uniq -D duplicate.txtEl sistema mostrará la salida de la siguiente manera.
This is a text file.
This is a text file.Omitir campos mientras busca duplicados
Si desea omitir una cierta cantidad de campos mientras hace coincidir las cadenas, puede usar la marca -f con el comando. La -f significa Field .
Considere el siguiente archivo de texto fields.txt .
192.168.0.1 TCP
127.0.0.1 TCP
354.231.1.1 TCP
Linux FS
Windows FS
macOS FSPara omitir el primer campo:
uniq -f 1 fields.txtProducción:
192.168.0.1 TCP
Linux FSEl comando mencionado anteriormente omitió el primer campo (las direcciones IP y los nombres del sistema operativo) y coincidió con la segunda palabra (TCP y FS). Luego, mostró la primera aparición de cada coincidencia como resultado.
Ignorar caracteres al comparar
Al igual que para omitir campos, también puede omitir caracteres. El indicador -s le permite especificar el número de caracteres que se deben omitir al hacer coincidir las líneas duplicadas. Esta función ayuda cuando los datos con los que está trabajando están en forma de lista de la siguiente manera:
1. First
2. Second
3. Second
4. Second
5. Third
6. Third
7. Fourth
8. FifthPara ignorar los dos primeros caracteres (las numeraciones de la lista) en el archivo list.txt :
uniq -s 2 list.txtProducción:
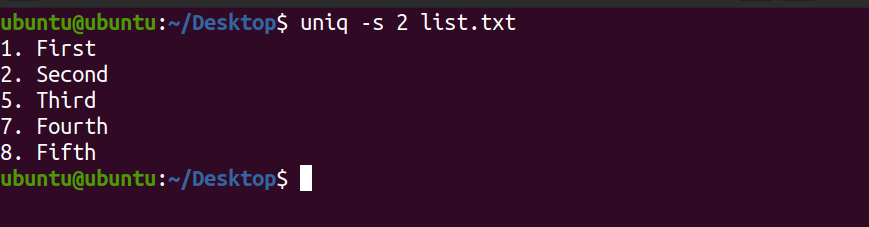
En el resultado anterior, los dos primeros caracteres se ignoraron y el resto de ellos se emparejaron para obtener líneas únicas.
Verifique el primer número N de caracteres en busca de duplicados
La bandera -w le permite verificar solo un número fijo de caracteres para ver si hay duplicados. Por ejemplo:
uniq -w 2 duplicate.txtEl comando antes mencionado solo coincidirá con los dos primeros caracteres e imprimirá líneas únicas, si las hay.
Producción:
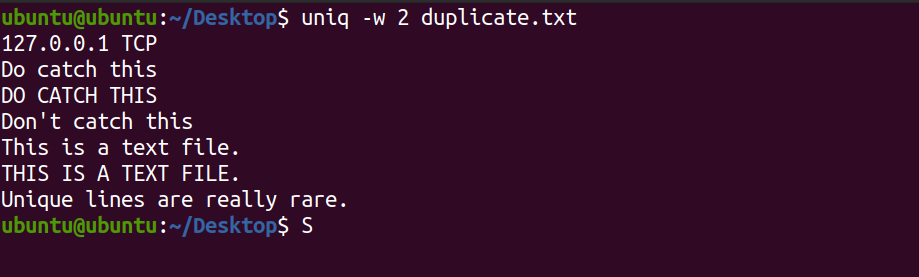
Eliminar la sensibilidad a mayúsculas y minúsculas
Como se mencionó anteriormente, uniq distingue entre mayúsculas y minúsculas al hacer coincidir líneas en un archivo. Para ignorar las mayúsculas y minúsculas, use la opción -i con el comando.
uniq -i duplicate.txtVerá el siguiente resultado.
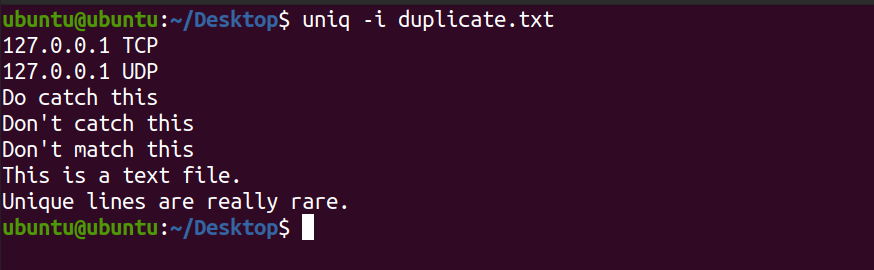
Observe que en la salida anterior, uniq no mostró las líneas HAGA ESTO y ESTE ES UN ARCHIVO DE TEXTO .
Enviar salida a un archivo
Para enviar la salida del comando uniq a un archivo, puede usar el carácter de redirección de salida ( > ) de la siguiente manera:
uniq -i duplicate.txt > otherfile.txtAl enviar una salida a un archivo de texto, el sistema no muestra la salida del comando. Puede verificar el contenido del nuevo archivo usando el comando cat .
cat otherfile.txtTambién puede utilizar otras formas de enviar la salida de la línea de comandos a un archivo en Linux .
Analizar datos duplicados con uniq
La mayor parte del tiempo, mientras administra servidores Linux, estará trabajando en la terminal o editando archivos de texto. Por lo tanto, saber cómo eliminar copias redundantes de líneas en un archivo de texto puede ser una gran ventaja para su conjunto de habilidades de Linux.
Trabajar con archivos de texto puede resultar frustrante si no sabe cómo filtrar y ordenar el texto en un archivo. Para facilitar su trabajo, Linux tiene varios comandos de edición de texto, como sed y awk, que le permiten trabajar de manera eficiente con archivos de texto y salidas de línea de comandos.