
Cómo encontrar y eliminar archivos duplicados en Linux usando fdupes
Cuando se trabaja con grandes cantidades de medios y documentos, es bastante común acumular varias copias del mismo archivo en su computadora. Inevitablemente, lo que sigue es un espacio de almacenamiento desordenado lleno de archivos redundantes, lo que provoca comprobaciones periódicas de archivos duplicados en su sistema.
Para ello, encontrará varios programas para identificar y eliminar archivos duplicados. Y resulta que fdupes es uno de esos programas para Linux. Así que sígalo mientras hablamos de fdupes y lo guiamos a través de los pasos para encontrar y eliminar archivos duplicados en Linux.
¿Qué es fdupes?
Fdupes es un programa basado en CLI para buscar y eliminar archivos duplicados en Linux. Se publica bajo la licencia MIT en GitHub .
En su forma más simple, el programa funciona ejecutando el directorio especificado a través de md5sum para comparar las firmas MD5 de sus archivos. Luego ejecuta una comparación byte por byte en ellos para identificar los archivos duplicados y asegurarse de que no queden duplicados.
Una vez que fdupes identifica los archivos duplicados, le da la opción de eliminarlos o reemplazarlos con enlaces físicos (enlaces a los archivos originales). Entonces, dependiendo de sus requisitos, puede proceder con una operación en consecuencia.
¿Cómo instalar fdupes en Linux?
Fdupes está disponible en la mayoría de las principales distribuciones de Linux, como Ubuntu, Arch, Fedora, etc. Según la distribución que esté ejecutando en su computadora, ejecute los comandos que se indican a continuación.
En sistemas basados en Ubuntu o Debian:
sudo apt install fdupesPara instalar fdupes en Fedora / CentOS y otras distribuciones basadas en RHEL:
sudo dnf install fdupesEn Arch Linux y Manjaro:
sudo pacman -S fdupes¿Cómo utilizar fdupes?
Una vez que haya instalado el programa en su computadora, siga los pasos a continuación para buscar y eliminar archivos duplicados.
Encontrar archivos duplicados con fdupes
Primero, comencemos por buscar todos los archivos duplicados en un directorio. La sintaxis básica para esto es:
fdupes path/to/directoryPor ejemplo, si desea buscar archivos duplicados en el directorio de Documentos , debe ejecutar:
fdupes ~/DocumentsProducción:
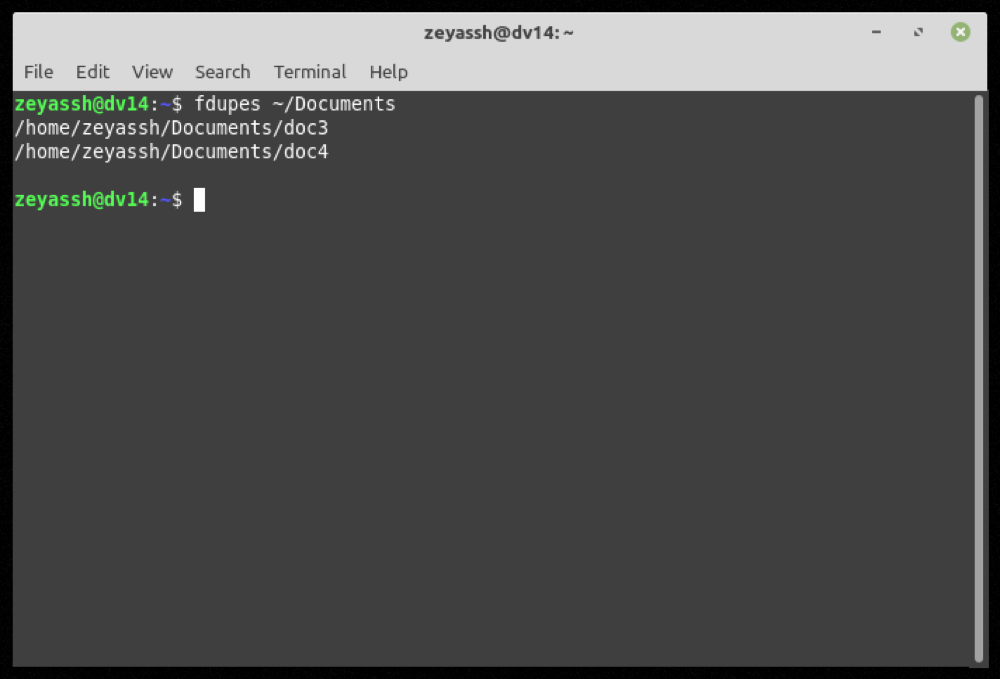
Si fdupes encuentra archivos duplicados en el directorio especificado, devolverá una lista de todos los archivos redundantes agrupados por conjunto, y luego podrá realizar más operaciones en ellos según sea necesario.
Sin embargo, si el directorio que ha especificado consta de subdirectorios, el comando anterior no identificará los duplicados dentro de ellos. En tales situaciones, lo que debe hacer es realizar una búsqueda recursiva para encontrar todos los archivos duplicados presentes dentro de los subdirectorios.
Para realizar una búsqueda recursiva en fdupes, use el indicador -r :
fdupes -r path/to/directoryPor ejemplo:
fdupes -r ~/DocumentsProducción:
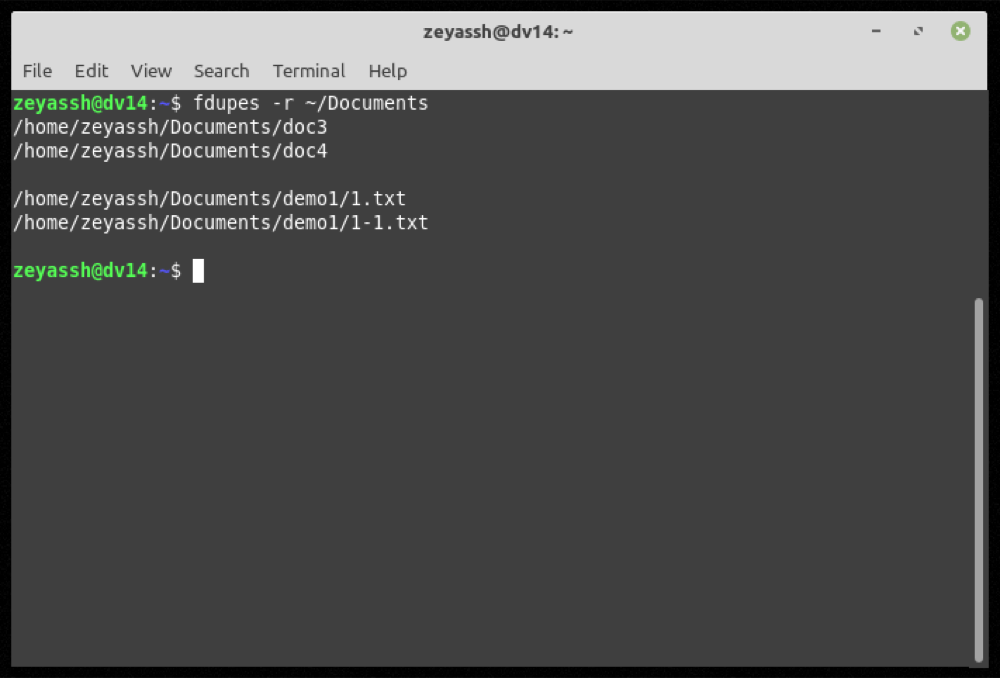
Si bien los dos comandos anteriores pueden encontrar fácilmente archivos duplicados dentro del directorio especificado (y sus subdirectorios), su salida también incluye archivos duplicados de longitud cero (o vacíos).
Aunque esta funcionalidad puede resultar útil cuando tiene demasiados archivos duplicados vacíos en su sistema, puede generar confusión cuando solo desea encontrar duplicados no vacíos en un directorio.
Afortunadamente, fdupes le permite excluir archivos de longitud cero de sus resultados de búsqueda usando la opción -n , que puede usar en sus comandos.
Nota: Puede excluir archivos duplicados no vacíos tanto en búsquedas normales como recursivas.
Para buscar solo archivos duplicados no vacíos en su máquina:
fdupes -n ~/DocumentsProducción:
Si está tratando con varios conjuntos de archivos duplicados, es aconsejable enviar los resultados a un archivo de texto para referencia futura.
Para hacer esto, ejecute:
fdupes path/to/directory > file_name.txt… donde ruta / al / directorio es el directorio en el que desea realizar la búsqueda.
Para buscar archivos duplicados en el directorio de Documentos y luego enviar la salida a un archivo:
fdupes /home/Documents > output.txtPor último, pero no menos importante, si desea ver un resumen de toda la información relacionada con los archivos duplicados en un directorio, puede usar el indicador -m en sus comandos:
fdupes -m path/to/directoryPara obtener información de archivo duplicado para el directorio de documentos :
fdupes -m ~/DocumentsProducción:
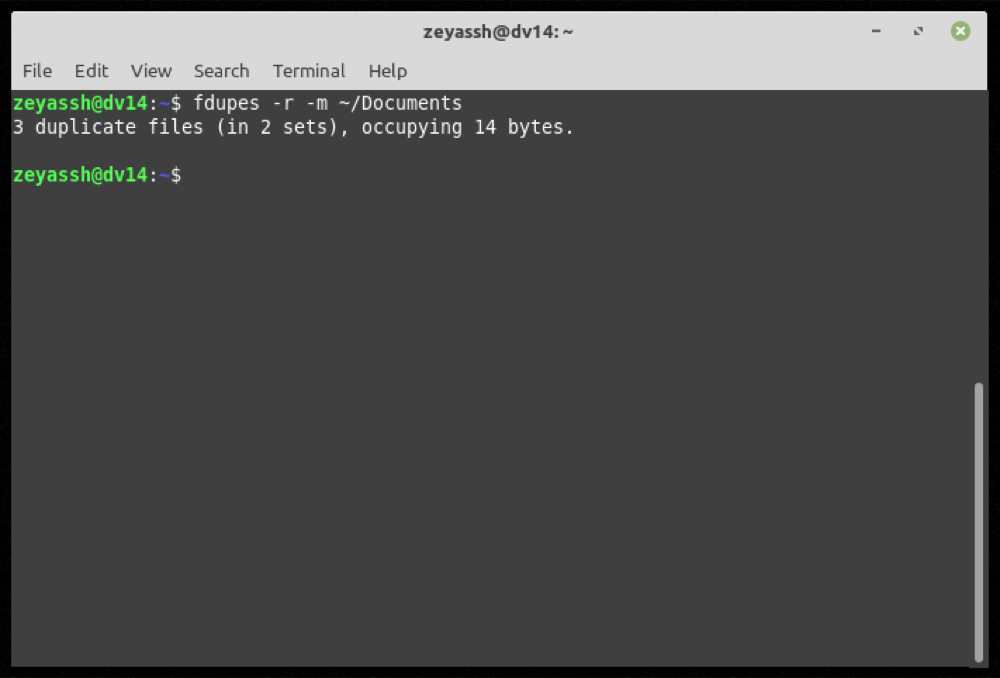
En cualquier momento durante el uso de fdupes, si desea ayuda con un comando o función, use la opción -h para obtener ayuda de la línea de comandos :
fdupes -h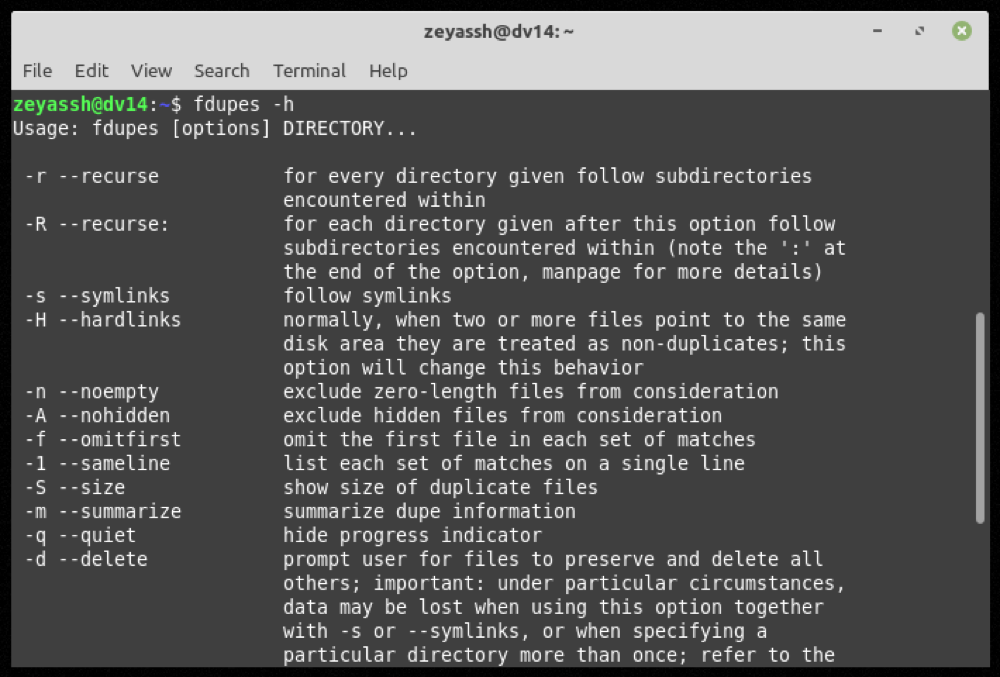
Eliminar archivos duplicados en Linux con fdupes
Una vez que haya identificado los archivos duplicados en un directorio, puede continuar con la eliminación / eliminación de estos archivos de su sistema para despejar el desorden y liberar espacio de almacenamiento.
Para eliminar un archivo duplicado, especifique la marca -d con el comando y presione Enter :
fdupes -d path/to/directoryPara eliminar archivos duplicados en la carpeta Descargas :
fdupes -d ~/DownloadsFdupes ahora le presentará una lista de todos los archivos duplicados en ese directorio y le dará la opción de preservar los que desea mantener en su computadora.
Por ejemplo, si desea conservar el primer archivo en el conjunto 1, debe ingresar 1 después de la salida de una búsqueda de fdupes y presionar Enter .
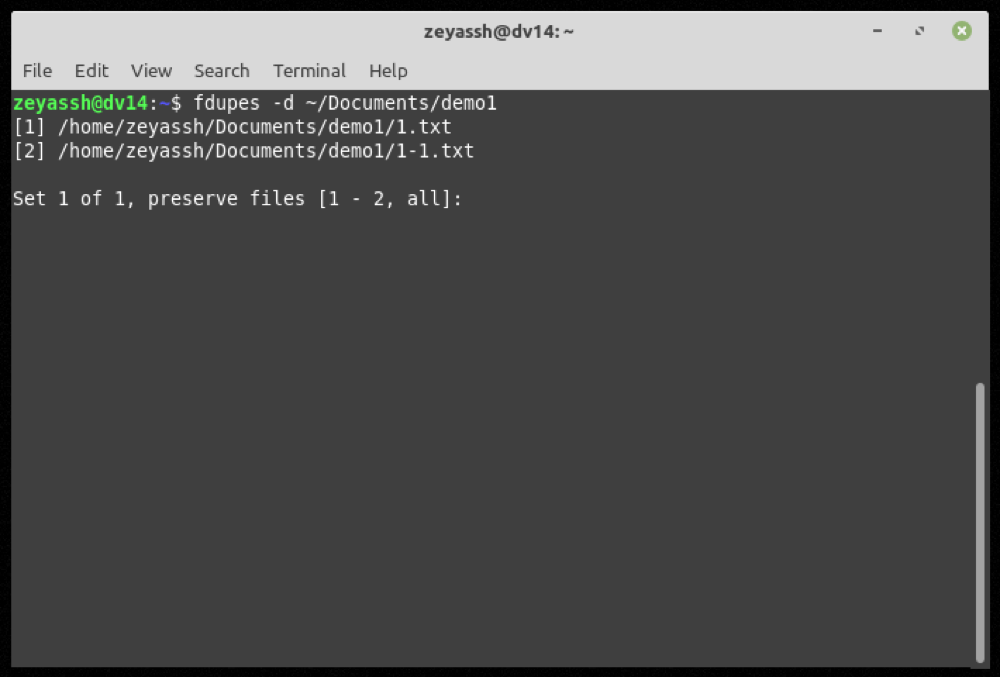
Además, si es necesario, también puede guardar varias instancias de archivo en un conjunto de archivos duplicados devueltos. Para esto, debe ingresar los números correspondientes a los archivos duplicados en una lista separada por comas y presionar Enter .
Por ejemplo, si desea guardar los archivos 1, 3 y 5, debe ingresar:
1,3,5En caso de que desee conservar la primera instancia de un archivo en cada conjunto de archivos duplicados y desee ignorar el mensaje, puede hacerlo incluyendo el modificador -N , como se muestra en el siguiente comando:
fdupes -d -N path/to/directoryPor ejemplo:
fdupes -d -N ~/DocumentsEliminación exitosa de archivos duplicados en Linux
Organizar archivos es una tarea tediosa en sí misma. Agregue a esto el problema que causan los archivos duplicados, y verá unas pocas horas de tiempo y esfuerzo desperdiciado en la organización de su almacenamiento desordenado.
Pero gracias a utilidades como fdupes, es mucho más fácil y eficiente identificar archivos duplicados y eliminarlos. Y la guía anterior debería ayudarlo con estas operaciones en su máquina Linux.
Al igual que los archivos duplicados, las palabras duplicadas y las líneas repetidas en un archivo también pueden ser frustrantes y requerir la eliminación de herramientas avanzadas. Si también enfrenta estos problemas, puede usar uniq para eliminar líneas duplicadas de un archivo de texto.